I’ve been noticing some fundamental misunderstandings around storage encryption – I see this most when dealing with XtremIO although plenty of platforms support it (VNX2 and VMAX). I hope this blog post will help someone who is missing the bigger picture and maybe make a better decision based on tradeoffs. This is not going to be a heavily technical post, but is intended to shed some light on the topic from a strategic angle.
Hopefully you already know, but encryption at a high level is a way to make data unreadable gibberish except by an entity that is authorized to read it. The types of storage encryption I’m going to talk about are Data At Rest Encryption (often abbreviated DARE or D@RE), in-flight encryption, and host-based encryption. I’m talking in this post mainly about SAN (block) storage, but these concepts also apply to NAS (file) storage. In fact, in-flight encryption is probably way more useful on a NAS array given the inherent security of FC fabrics. But then, iSCSI, and it gets cloudier.
Before I start, security is a tool and can be used wisely or poorly with equivalent results. Encryption is security. All security, and all encryption, is not great. Consider the idea of cryptographic erasure, by which data is “deleted” merely because it is encrypted and nobody has the key. Ransomware thrives on this. You are looking at a server with all your files on it, but without the key they may as well be deleted. Choosing a security feature for no good business reason other than “security is great” is probably a mistake that is going to cause you headaches.
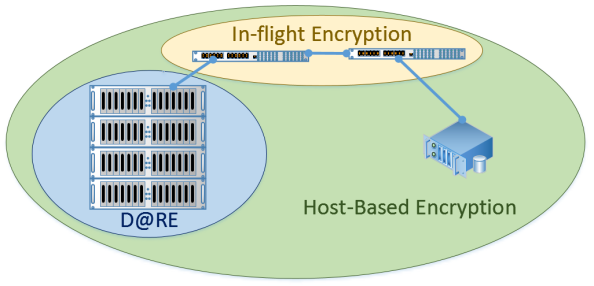
Here is a diagram with 3 zones of encryption. Notice that host-based encryption overlaps the other two – that is not a mistake as we will see shortly.
Data At Rest Encryption
D@RE of late is typically referring to a storage arrays ability to encrypt data at the point of entry (write) and decrypt on exit (read). Sometimes this is done with ASICs on an array or I/O module, but it is often done with Self Encrypting Drives (SEDs). However the abstract concept of D@RE is simply that data is encrypted “at rest,” or while it is sitting on disk, on the storage array.
This might seem like a dumb question, but it is a CRUCIAL one that I’ve seen either not asked or answered incorrectly time and time again: what is the purpose of D@RE? The point of D@RE is to prevent physical hardware theft from compromising data security. So, if I nefariously steal a drive out of your array, or a shelf of drives out of your array, and come up with some way to attach them to another system and read them, I will get nothing but gibberish.
Now, keep in mind that this problem is typically far more of an issue on a small server system than it is a storage array. A small server might just have a handful of drives associated with it, while a storage array might have hundreds, or thousands. And those drives are going to be in some form of RAID protection which leverages striping. So even without D@RE the odds of a single disk holding meaningful data is small, though admittedly it is still there.
More to the point, D@RE does not prevent anyone from accessing data on the array itself. I’ve heard allusions to this idea that “don’t worry about hackers, we’ve got D@RE” which couldn’t be more wrong, unless you think hackers are walking out of your data center with physical hardware. If the hackers are intercepting wire transmissions, or they have broken into servers with SAN access, they have access to your data. And if your array is doing the encryption and someone manages to steal the entire array (controllers and all) they will also have access to your data.
D@RE at the array level is also one of the easiest to deal with from a management perspective because usually you just let the array handle everything including the encryption keys. This is mostly just a turn it on and let it run solution. You don’t notice it and generally don’t see any fall out like performance degradation from it.
In-Flight Encryption
In-flight encryption is referring to data being encrypted over the wire. So your host issues a write to a SAN LUN, and that traverses your SAN network and lands on your storage array. If data is encrypted “in-flight,” then it is encrypted throughout (at least) the switching.
Usually this is accomplished with FC fabric switches that are capable of encryption. So the switch that sees a transmission on an F port will encrypt it, and then transmit it encrypted along all E ports (ISLs) and then decrypt it when it leaves another F port. So the data is encrypted in-flight, but not at rest on the array. Generally we are still talking about ASICs here so performance is not impacted.
Again let’s ask, what is the purpose of in-flight encryption? In-flight encryption is intended to prevent someone who is sniffing network traffic (meaning they are somehow intercepting the data transmissions, or a copy of the data transmissions, over the network) from being able to decipher data.
For local FC networks this is (in my opinion) not often needed. FC networks tend to be very secure overall and not really vulnerable to sniffing. However, for IP based or WAN based communication, or even stretched fabrics, it might be sensible to look into something like this.
Also keep in mind that because data is decrypted before being written to the array, it does not provide the physical security that D@RE does, nor does it prevent anyone from accessing data in general. You also sometimes have the option of not decrypting when writing to the array. So essentially the data is encrypted when leaving the host, and written encrypted on the array itself. It is only decrypted when the host issues a read for it and it exits the F port that host is attached to. This results in you having D@RE as well with those same benefits. A real kicker here becomes key management, because in-flight encryption can be removed at any time without issue. You can remove or disable in-flight encryption and not see any change in data because at the ends it is unencrypted. However, if the data is written encrypted on the array, then you MUST have those keys to read that data. If you had some kind of disaster that compromised your switches and keys, you would have a big array full of cryptographically erased data.
Host Based Encryption
Finally, host-based encryption is any software or feature that encrypts LUNs or files on the server itself. So data that is going to be written to files (whether SAN based or local files) is encrypted in memory before the write actually takes place.
Host-based encryption ends up giving you both in-flight encryption and D@RE as well. So when we ask the question, what is the purpose of host-based encryption?, we get the benefits we saw from in-flight and D@RE, as well as another one. That is the idea that even with the same hardware setup, no other host can read your data. So if I were to forklift your array, fabric switches, and get an identical server (hardware, OS, software) and hook it up, I wouldn’t be able to read your data. Depending on the setup, if a hacker compromises the server itself in your data center, they may not be able to read the data either.
So why even bother with the other kinds of encryption? Well for one, generally host-based encryption does incur a performance hit because it isn’t using ASICs. Some systems might be able to handle this but many won’t be able to. Unlike D@RE or in-flight, there will be a measurable degradation when using this method. Another reason is that key management again becomes huge here. Poor key management and a server having a hardware failure can lead to that data being unreadable by anyone. And generally your backups will be useless in this situation as well because you have backups of encrypted data that you can’t read without the original keys.
And frankly, usually D@RE is good enough. If you have a security issue where host-based encryption is going to be a benefit, usually someone already has the keys to the kingdom in your environment.
Closing Thoughts
Hopefully that cleared up the types of encryption and where they operate.
Another question I see is “can I use one or more at the same time?” The answer is yes, with caveats. There is nothing that prevents you from using even all 3 at the same time, even though it wouldn’t really make any sense. Generally you want to avoid overlapping because you are encrypting data that is already encrypted which is a waste of resources. So a sensible pairing might be D@RE on the array and in-flight on your switching.
A final HUGELY important note – and what really prompted me to write this post – is to make sure you fully understand the effect of encryption on all of your systems. I have seen this come up in a discussion about XtremIO using D@RE paired with host-based encryption. The question was “will it work?” but the question should have been “should we do this?” Will it work? Sure, there is nothing problematic about host-based encryption and XtremIO D@RE interacting, other than the XtremIO system encrypting already encrypted data. What is problematic, though, is the fact that encrypted data does not compress, and most encrypted data won’t dedupe either…or at least not anywhere close to the level of unencrypted data. And XtremIO generally relies on its fantastic inline compression and dedupe features to fit a lot of data on a small footprint. XtremIO’s D@RE happens behind the compression and deduplication, so there is no issue. However host-based encryption will happen ahead of the dedupe/compression and will absolutely destroy your savings. So if you wanted to use the system like this, I would ask, how was it sized? Was it sized with assumptions about good compression and dedupe ratios? Or was it sized assuming no space savings? And, does the extra money you will be spending for the host-based encryption product and the extra money you will be spending on the additional required storage justify the business problem you were trying to solve? Or was there even a business problem at all? A better fit would probably be something like a tiered VNX2 and FAST cache which could easily handle a lot of raw capacity and use the flash where it helps the most.
Again, security is a tool, so choose the tools you need, use them judiciously, and make sure you fully understand their impact (end-to-end) in your environment.



